Data Preprocessing

scikit-learn
This chapter introduces the package
scikit-learn, the swiss-army knife
for data preprocessing, transformation and machine learning.
We will continue to work with the Portuguese retail bank data
set1 and preprocess it further. Alongside we start to explore
scikit-learn's functionalities.
Check-out the excellent scikit-learn documentation.
Prerequisites
If you have followed the previous chapter closely, your project structure looks like this:
📁 bank_marketing/
├── 📁 .venv/
├── 📁 data/
├───── 📄 bank.tsv
├───── 📄 bank-merged.csv
└───── 📄 bank-social.csv
With bank-merged.csv being the "inner" join of bank.csv and
social.csv, minus all duplicated customer data.
If you are missing the file bank-merged.csv, we strongly recommend you to
go back and complete the previous chapter. For the sake of completeness,
we provide a distilled version of the code from
Data preparation:
Merge the data sets
Again, we urge you to use a virtual environment which by now, should be second nature anyway.
Create a new notebook
To follow along, create a new Jupyter notebook within your project.
Missing values
After dropping duplicates and merging the data, the next step is to check for missing values. First, we read the data.
We chain a couple of methods to count the missing values in each column.
The isna() method checks each element and whether it is a missing
value or not. The result is a DataFrame with boolean values of the same
shape as the initial DataFrame (in our case data), with True
being a missing value. With the chaining of sum() we simply sum the
True values (missing values) for each column.
A truncated version of the output is shown below:
| Column | Missing Values |
|---|---|
| id | 0 |
| age | 0 |
| default | 0 |
| housing | 0 |
| ... | ... |
| job | 0 |
| marital | 0 |
| education | 0 |
| ... | ... |
It seems like the columns have no missing values. To sum missing values of
the whole DataFrame, we can chain another sum().
The output once more indicates that the whole data set has 0
missing values. So far so good, but this is not the end of the story (who
saw that coming 🤯).
Although, it seems like we don't have to bother with missing values, they are simply a bit more hidden.
Missing values in disguise
pandas considers types like None or np.nan as
missing. However in practice, missing values are encoded in various ways.
For instance, strings like "NA" or integers like -999
are used. Consequently, we can't detect these ways of encoding with
simply calling isna().
Since we have to manually detect these encoded missing values, it is essential to have a good understanding of the data. Let's get more familiarized with the data.
Visit the UCI Machine Learning Repository here which also hosts the data set and some additional information. Interestingly, the section Dataset Information states:
Has Missing Values?
No
Although that might be technical correct (the data contains no empty values), we have to dig deeper.
Detect the encoding of missing values
Open the UCI Machine Learning Repository. Look at the Variables Table. How are the missing values encoded in the data set?
Use the following quiz question to validate your answer.
Remember, the bigger picture
by getting more familiar with the data, we can train a better fitting
model to predict the target variable y (subscribed to term deposit or
not).
How are missing values encoded in this specific data set?
Missing values uncovered
Now that we uncovered the encoding of missing values, we replace them with
None to properly detect them and handle them more easily.
Replace encoding with None
Since, you've detected the particular encoding of missing values, replace
them with None across the whole data frame.
Use the DataFrame.replace() method and read the
docs,
especially the Examples section for usage guidance.
After solving the question, we (again) sum up the missing values per column.
A truncated version of the output:
| Column | Missing Values |
|---|---|
| id | 0 |
| age | 0 |
| default | 760 |
| housing | 97 |
| ... | ... |
| job | 35 |
| marital | 11 |
| education | 161 |
| ... | ... |
At first glance, a lot of columns contain missing values. Let's calculate the ratio to get a better feeling.
count_missing = data.isna().sum()
n_rows = len(data)
missing_ratio = (count_missing / n_rows) * 100
print(missing_ratio.round(2))
| Column | Missing Values (%) |
|---|---|
| id | 0.00 |
| age | 0.00 |
| default | 19.35 |
| housing | 2.47 |
| ... | ... |
| job | 0.89 |
| marital | 0.28 |
| education | 4.10 |
| ... | ... |
Compared to the initial observation where we found 0
missing values across the whole data set, it's a stark contrast.
Looking at the attribute default, nearly a fifth of the observations are missing (19.35 %). Other attributes contain less missing values, yet we still need to handle them. Therefore, we explore different strategies to deal with missing values.
Info
Though it might not seem much, being able to detect these missing values will prove invaluable in the future.
By identifying and properly handling these gaps, we might be able to train a better fitting model as unaddressed missing values can lead to biased predictions. Most importantly, most algorithms can't handle missing values at all.
Sources
We have extensively covered how to detect missing values but have not talked about their possible origins.
The reasons for missing values can be manifold:
- Data collection issues
- Non-responses in a survey
- Equipment failures
- Simple human errors when entering data
- Technical challenges
- Preprocessing errors (i.e., merging data sets from multiple sources)
- Intentional omissions
- Privacy concerns or legal restrictions
... or the information is simply not available.
Drop columns/rows
One simple way to handle missing values is to drop (i.e. remove) the respective columns which contain any missing values.
axis=1 specified the columns to be dropped.
To comprehend the impact of this operation, we calculate the number of columns that were removed.
This operation removed6 out of 21 columns/attributes.
Remove rows with missing values
Contrary, we can leave all columns and instead drop the rows containing missing values.
- Use the
DataFrame.dropna()method to remove rows with missing values. - Calculate the number of rows that were removed.
Set a threshold
Instead of dropping all rows/columns with gaps, we can set a threshold to only drop columns/rows with a certain amount of missing values.
To specify a threshold, make use of the thresh parameter, which takes an
int value of non-missing values that a column/row must have,
to not be dropped.
As an example, we would like to remove all columns holding more than 10 % missing values.
import math
threshold = 0.1 # 10 % threshold
threshold = (1 - threshold) * len(data)
print(threshold)
threshold = math.ceil(threshold) # (1)!
print(threshold)
data_dropped_threshold = data.dropna(axis=1, thresh=threshold)
diff = data.shape[1] - data_dropped_threshold.shape[1]
print(f"Number of columns dropped: {diff}")
- The
math.ceil()function is used to round up the threshold value to the next integer.
A single column was dropped and therefore exceeded the 10 % threshold of missing values.
Depending on the data at hand, dropping rows or columns might be a valid option, if you're dealing with a small number of missing values. However, in other cases these operations might lead to a significant loss of information. Since, we are dealing with a substantial amount of missing values, we are looking for more sophisticated ways to handle them.
Imputation techniques
What about filling in the missing values? The process of replacing missing values is called imputation.
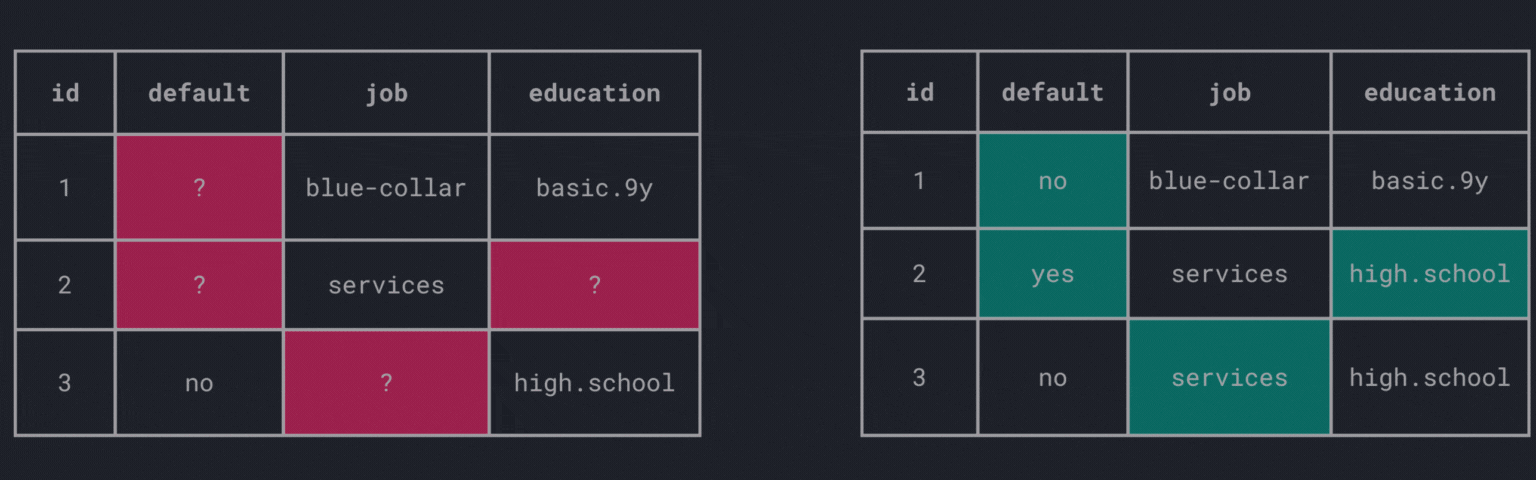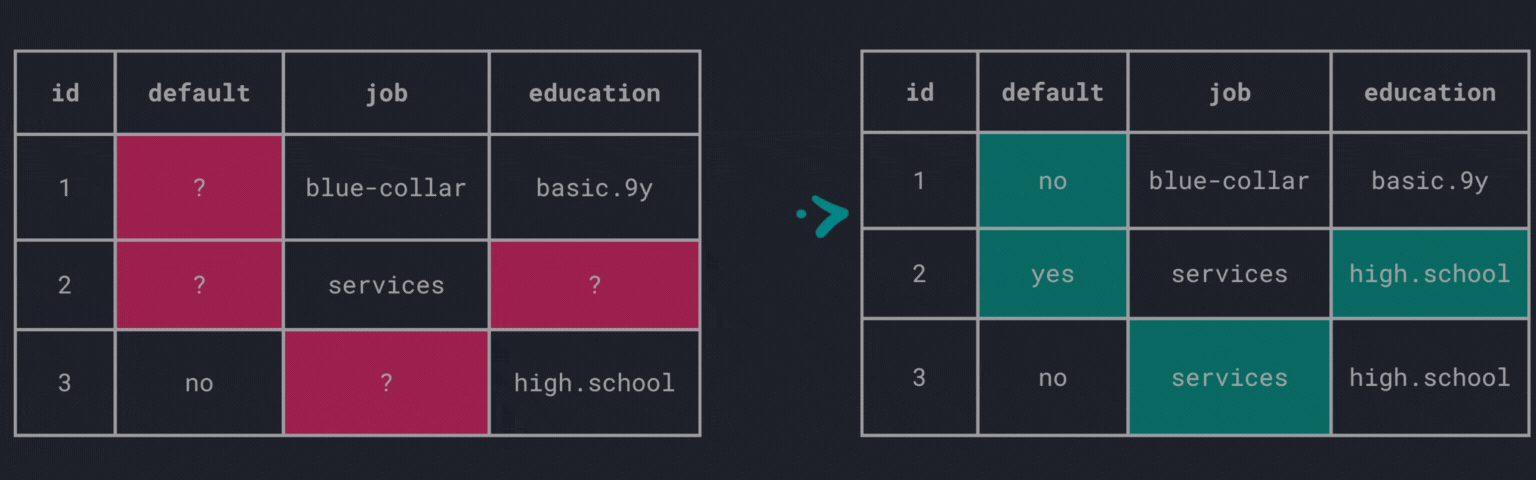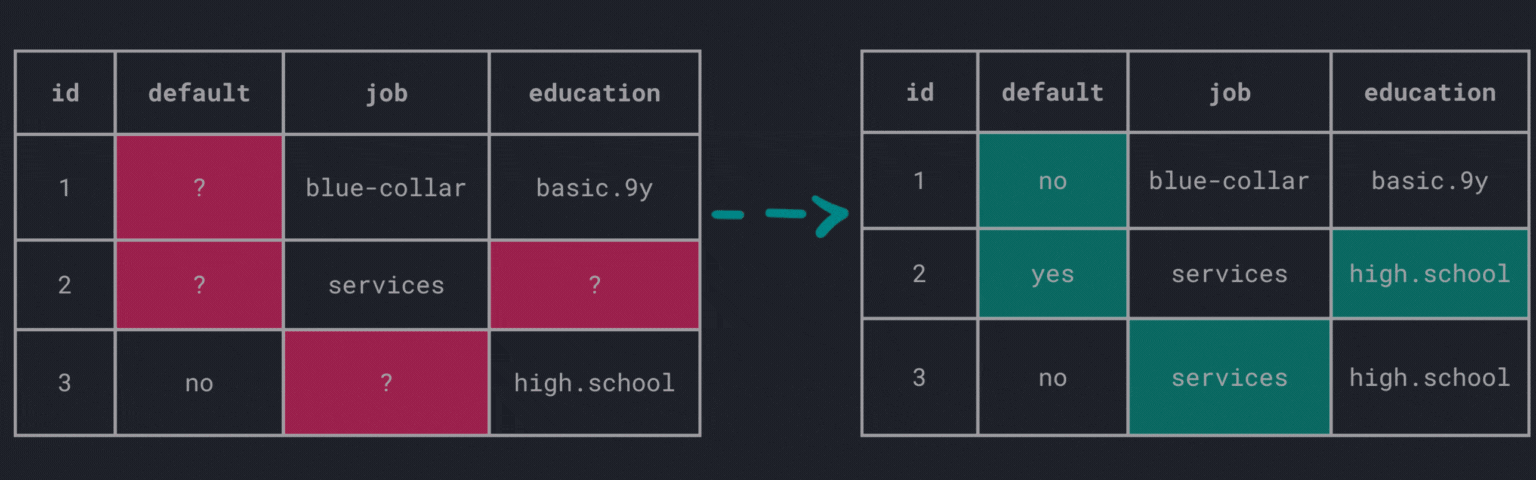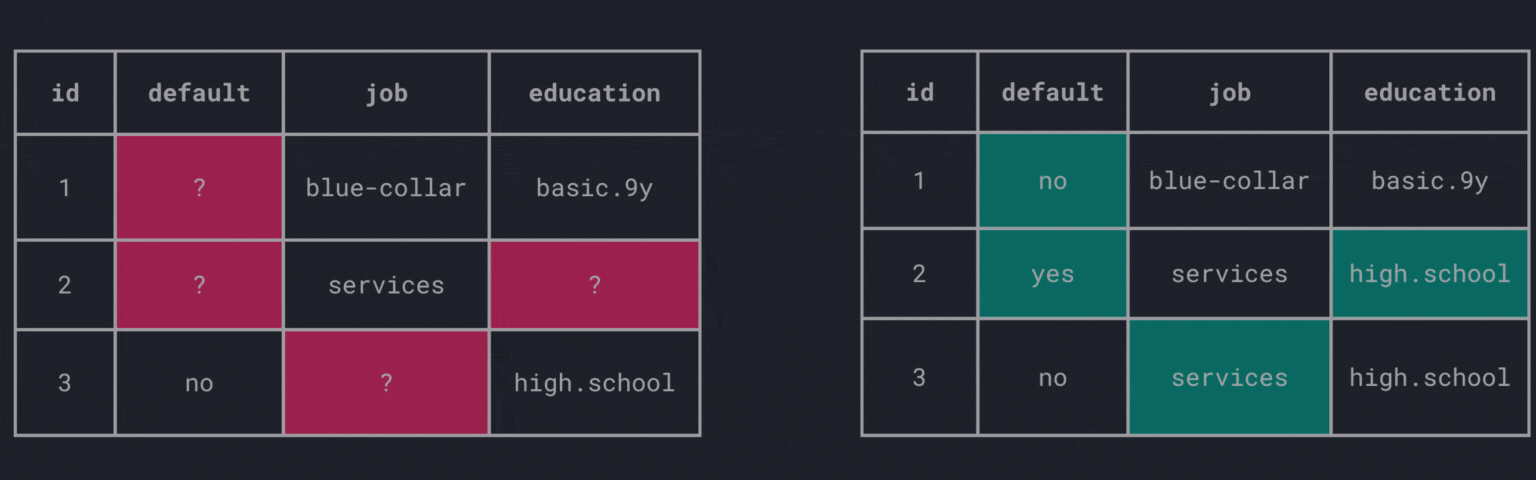
There are various imputation techniques available, each with its own advantages and disadvantages.
Fill manually
Of course, there is always the option to fill the values manually which could be time-consuming and infeasible for large data sets.
Global constant
The simplest way to impute missing values is to replace them with a global constant, i.e., filling gaps across all columns with the same value.
This method is straightforward and easy to implement. However, there are some drawbacks:
- how to choose the global constant?
- introduces further challenges with mixed attributes (i.e., nominal/ordinal and numerical attributes)
Central tendency
Another common approach is to replace missing values with the mean, median, or mode of the respective column.
Fill a nominal attribute with the mode:
Fill a numerical attribute with the mean:
Info
Since the bank data does not contain any numerical attribute with missing values, the above code snippet assumed gaps in age. As there are none, the operation did not change the data.
Machine Learning
Lastly, we can use machine learning algorithms to predict the missing values. The idea is to estimate the missing values based on the other attributes. Linear regression, k-nearest neighbors, or decision trees are common choices.
Info
As we have not covered machine learning yet, we won't get into the details. But feel free to return to this section. Especially, this scikit-learn comparison of imputation techniques (including k-nearest neighbors) is a good starting point for further exploration.
Transformation
Step by step, we are getting closer to actually training a machine learning model. Beforehand, we introduce data transformations that are commonly applied to improve the fit of the model.
For starters, install the scikit-learn package within your activated
environment.
From now on, we will heavily use scikit-learn's functionalities.
Discretize numerical attributes
When dealing with noisy data, it is often beneficial to discretize numerical (continuous) attributes.
Noise in data
Noise is a random error or variance in a measured variable. It is meaningless information that can distort the data.
Noise can be identified using basic statistical methods and visualization techniques like boxplots or scatter plots.
The process of discretizing is called binning. I.e., the continuous data is separated into intervals (bins). Bins can generally lead to a smoothing effect which in turn reduce the noise.
As an example, we pick the attribute age and visualize it with a boxplot.
Create a static boxplot
To create a static version of the boxplot, perfect for a quick overview:
- The
plot()method usesmatplotlibas backend.

Since, age contains outliers, we discretize the attribute age into five bins with the same width.
from sklearn.preprocessing import KBinsDiscretizer
bins = KBinsDiscretizer(n_bins=5, strategy="uniform", encode="ordinal")
bins.fit(data[["age"]])
age_binned = bins.transform(data[["age"]]) # (1)!
- The additional square brackets in
data[["age"]]are used to select the column age as aDataFrame(instead of aSeries). This is necessary for thetransform()method as a two-dimensional input is required.
The above snippet returns 5 bins with a width of 14 years. Inspect the bin edges with:
Though the actual binning is just two three lines of code, we have a couple of things to dissect.
Working with scikit-learn
Although the package is named scikit-learn, it is imported as
import sklearn. Package names on
PyPI (Python Package Index)
can be different from the import name.
scikit-learn frequently uses classes (e.g., KBinsDiscretizer)
to represent different models and preprocessing techniques. Two important
methods that many of these classes implement are fit and transform.
-
fit(X): This method is used to learn the parameters from the data (referred to asX). -
transform(X): This method is used to apply the learned parameters to the dataX.
Put simply, think about the fit(X) method as scikit-learn takes
a look at the data and learns from it. The transform(X)
method then transfers this knowledge and applies it to the data.
The fit_transform() method combines both of these steps in one.
Alternatively, use strategy="quantile" to bin the data based on
quantiles and thus create bins with the same number of observations.
bins = KBinsDiscretizer(n_bins=5, strategy="quantile", encode="ordinal")
age_binned = bins.fit_transform(data[["age"]])
print(bins.bin_edges_)
No matter the strategy "uniform" or "quantile", a
matrix is returned with the
bin identifier encoded as an integer value.
Normalization
Normalization is a common preprocessing step to scale the data to a standard range, which can improve the performance and training stability of machine learning models. Two popular normalization techniques are Min-Max normalization and Z-Score normalization.
Min-Max Normalization
Min-Max normalization scales the data to a fixed range, usually [0, 1].
Definition: Min-Max Normalization
where \(X\) is the original value, \(X_{min}\) is the minimum value of the feature, and \(X_{max}\) is the maximum value of the feature.
This technique is useful when you want to ensure that all features have the same scale without distorting differences in the ranges of values.
To illustrate the normalization, we use the attribute euribor3m (3 month Euribor rate).
Euribor is short for Euro Interbank Offered Rate. The Euribor rates are based on the average interest rates at which a large panel of European banks borrow funds from one another.
from sklearn.preprocessing import MinMaxScaler
print(f"X_min: {data['euribor3m'].min()}, X_max: {data['euribor3m'].max()}")
scaler = MinMaxScaler()
scaler.fit(data[["euribor3m"]])
scaled = scaler.transform(data[["euribor3m"]])
print(scaled)
print(f"Min: {scaled.min()}, Max: {scaled.max()}")
X_min: 0.635, X_max: 4.97
[[0.15640138]
[0.97347174]
[0.99815456]
...
[0.16585928]
[0.99907728]
[0.80392157]]
Min: 0.0, Max: 1.0
Normalization of new data
Assume new data is added:
We would like to transform these three new interest rates using the Min Max normalization. Remember that theMinMaxScaler was already fitted on the original
data with \(X_{min}=0.635\) and \(X_{max}=4.97\).
Answer the following quiz question. Look at the formula again and try to answer the question without executing code.
What happens if you call transform(new_data)?
Z-Score Normalization
Z-Score normalization, also known as standardization, scales the data based on the mean and standard deviation of an attribute.
Definition: Z-Score Normalization
where \(\mu\) is the mean of the feature and \(\sigma\) is the standard deviation.
This technique centers the data around zero with a standard deviation of one, which is useful for algorithms assuming normally distributed data.
Apply Z-Score normalization
Use the StandardScaler
from scikit-learn to apply Z-Score normalization to the attribute
campaign (number of times a customer was contacted).
- Fit the
StandardScaleron the data. - Transform the data.
- Calculate and print the mean and standard deviation of the transformed data.
One-Hot Encoding
So far we have focused on numerical attributes. But what about categorical variables? Since, many machine learning algorithms can't handle categorical attributes directly, they need to be encoded. One common technique is to one-hot encode these attributes.
Imagine the toy example below to illustrate the concept of one-hot encoding on the feature job.
Definition: One-Hot Encoding
One-hot encoding is a technique to convert categorical attributes into numerical attributes. Each category is represented as a binary vector where only one bit is set to 1 (hot) and the rest are set to 0 (cold).
The class OneHotEncoder
from scikit-learn can be used to encode categorical attributes to a one-hot
encoded representation.
Apply One-Hot Encoding
Use the OneHotEncoder to encode the the attribute job from the
following toy DataFrame (same as in the video).
toy_data = pd.DataFrame(
{"id": [1, 2, 3, 4], "job": ["engineer", "student", "teacher", "student"]}
)
- Apply an instance of
OneHotEncoder(sparse_output=False)to job. - Check if the resulting matrix matches with the one in the video.
Label Encoding
Lastly, we introduce label encoding. Label encoding is another technique to encode categorical attributes. Instead of creating a binary vector for each category, label encoding assigns a unique integer to each category.
scikit-learn's LabelEncoder
is specifically designed to encode the target variable (i.e., the attribute we
want to predict). In our case, we apply the LabelEncoder to the column named
"y".
"y" represents if the client
subscribed to a term deposit or not.
from sklearn.preprocessing import LabelEncoder
print(f"Unique values: {data['y'].unique()}")
encoder = LabelEncoder()
y_encoded = encoder.fit_transform(data["y"])
print(y_encoded)
As "y" contains the values "yes" and "no",
we retrieve a binary representation with 0 and 1.
Recap
In this chapter, we have extensively covered missing values. The challenges to detect them in the first place and how to properly encode them. We explored different strategies to deal with missing values, from dropping columns/rows to imputation techniques.
Using scikit-learn we were able to easily apply transformation to the
Portuguese retail bank data set. We discretized (KBinsDiscretizer) numerical
attributes, normalized them (MinMaxScaler, StandardScaler), and encoded
categorical features with one-hot encoding (OneHotEncoder). Lastly, we
briefly covered the encoding of target variables with the LabelEncoder.
With all these preprocessing steps, we are now well-equipped to dive into the machine learning part and are closer to training our first model.
-
Decision Support Systems, Volume 62, June 2014, Pages 22-31: https://doi.org/10.1016/j.dss.2014.03.001 ↩