Measures of Correlation
This chapter covers the measures of linear relationships, specifically covariance and correlation. These measures help in characterizing the linear relationship between two variables, if such a relationship exists.
Covariance
In the previous univariate parts, the metrics focused only on a single variable. Covariance allows us to determine the relationship between two variables.
Definition: Covariance
where \(X\) and \(Y\) are variables consisting of \(N\) values, and \( \bar{x} \) and \( \bar{y} \) are their respective means.
The name suggests that it is a type of 'variance,' as \( \text{cov}(X, X) = \sigma^2(X) \).
import plotly.express as px
df = px.data.tips()
Covariance = df['total_bill'].cov(df['tip'], ddof=0)
print(f"Covariance: {Covariance}")
By default, the degree of freedom ddof=1. In this case the population formular will be used. For the sample formular, the ddof=0 needs to be set.
Example: Covariance of House Price
Given is a table with the size and price of houses. Determine the covariance.
Solution
The covariance between \(X\) and \(Y\) is \(1,486,000 \, \text{m}^2\text{€}\).
Code
import pandas as pd
# Create a DataFrame
df = pd.DataFrame([(60, 330000), (72, 490000), (111, 600000), (67, 400000) , (90, 455000)], columns=['size', 'price'])
# Calculate covariance
house_cov = df['size'].cov(df['price'], ddof=0) # ddof=0 --> Formlar for sample | ddof=1 --> Formlar for population (default)
print(f"Covariance: {house_cov}")
Interpretation of Covariance:
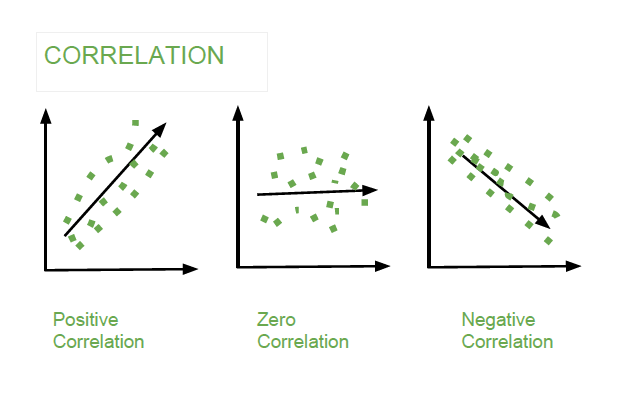
- Covariance indicates the direction of the relationship:
- \(>0\): Positive relationship (if \(X\) increases, \(Y\) increases)
- \(=0\): No relationship
- \(<0\): Negative relationship (if \(X\) increases, \(Y\) decreases)
- Covariance does not provide information about the strength of the relationship since it is not dimensionless.
- To quantify the strength, we use a normalized measure called the correlation coefficient.
Correlation Coefficient
Pearson
The Pearson correlation coefficient expresses both the direction and strength of the linear relationship between two variables. It is a normalized form of covariance and is symmetric: \( \rho_{X,Y} = \rho_{Y,X} \).
Definition: Pearson Correlation Coefficient
where \(X\) and \(Y\) are metric variables, \( \sigma_x \) and \( \sigma_y \) are their standard deviations, and \( \text{cov}(X, Y) \) is the covariance.
Pearson = df['total_bill'].corr(df['tip'],method='pearson')
print(f"Pearson Correlation Coefficient: {Pearson}")
Example: Pearson Correlation Cofficient of House Price
Given is a table with the size and price of houses.
Additionally, we already know:Determine the Pearson correlation coefficient.
Solution
The correlation coefficient between \(X\) and \(Y\) is \(0.89\).
Code
import pandas as pd
# Create a DataFrame
df = pd.DataFrame([(60, 330000), (72, 490000), (111, 600000), (67, 400000) , (90, 455000)], columns=['size', 'price'])
# Calculate pearson correlation coefficient
house_pearson = df['size'].corr(df['price'],method='pearson')
print(f"Pearson Correlation Coefficient: {house_pearson}")
Interpretation of the Pearson Correlation Coefficient :
- The Pearson correlation coefficient has no dimesion.
- Its value ranges between \([-1 \dots 1]\) (according to the standard terminology by Jacob Cohen, 1988):
- \(0\): No correlation
- \(> \pm 0.1\): Weak correlation
- \(> \pm 0.3\): Moderate correlation
- \(> \pm 0.5\): Strong correlation
- \(\pm 1\): Perfect positive/negative correlation (one variable can be derived from the other)
Spearman
Covariance and the Pearson correlation coefficient require variables to be at least metric. When one of the variables is ordinal, the rank correlation should be calculated, with Spearman's method being a common choice.
Spearman = df['total_bill'].corr(df['tip'],method='spearman')
print(f"Spearman Correlation Coefficient: {Spearman}")
In order for df.corr() to deal with ordinal data, the input needs to be numeric. This means that for ordinal data consisting of letters, the data needs to be mapped:
day_order = {
'Thur' : 4,
'Fri' : 5,
'Sat' : 6,
'Sun' : 7
}
df['day_ord'] = df['day'].map(day_order)
Spearman = df['day_ord'].corr(df['size'],method='spearman')
print(f"Spearman Correlation Coefficient: {Spearman}")
The interpretation of Spearman's rank correlation is similar to Pearson's.
Definition: Spearman Rank Correlation Coefficient
with \(X\) and \(Y\) as variables consisting of \(N\) values and ranks \(R(x_i)\) and \(R(y_i)\).
Rank Formation
-
The rank corresponds to the position a value holds when all values are arranged in order.
Example: Ranking of Values
\(x_i\) 2.17 8.00 1.09 2.01 \(R(x_i)\) 3 4 1 2 -
For identical values, the average rank (mean of the relevant ranks) is used.
Example: Ranking of Equal Values
\(x_i\) 1.09 2.17 2.17 2.17 3.02 4.50 \(R(x_i)\) 1 3 3 3 5 6 with \( (2+3+4)/3 = 3 \)
Example: Spearman Correlation Coefficient of House Price
Given is a table with the size and price of houses.
Determine the Spearman correlation coefficient.Solution
| Size | R(Size) | Price | R(Price) | \( d_i \) |
|---|---|---|---|---|
| 60 | 1 | 330k | 1 | 0 |
| 72 | 3 | 490k | 4 | -1 |
| 111 | 5 | 600k | 5 | 0 |
| 67 | 2 | 400k | 2 | 0 |
| 90 | 4 | 455k | 3 | 1 |
The Spearman correlation coefficient between \(X\) and \(Y\) is \(0.9\).
Code
import pandas as pd
# Create a DataFrame
df = pd.DataFrame([(60, 330000), (72, 490000), (111, 600000), (67, 400000) , (90, 455000)], columns=['size', 'price'])
# Calculate spearman correlation coefficient
house_spearman = df['size'].corr(df['price'],method='spearman')
print(f"Spearman Correlation Coefficient: {house_spearman}")
Scatter Plot
A scatter plot provides a graphical representation of the relationship between two metric variables on a Cartesian coordinate system.
import plotly.express as px
df = px.data.iris()
fig = px.scatter(df, x="sepal_width", y="sepal_length")
fig.show()
Each data pair is treated as a coordinate and is represented by a point on the plot. This allows for identifying relationships, patterns, or trends between the variables.
Example: Scatter Plot of House Prices
Code
import pandas as pd
# Create a DataFrame
df = pd.DataFrame([(60, 330000), (72, 490000), (111, 600000), (67, 400000) , (90, 455000)], columns=['size', 'price'])
import plotly.express as px
# Create a scatter plot
fig = px.scatter(df, x="size", y="price")
# Adjust the plot
fig.update_layout(
xaxis_title_text='Size',
yaxis_title_text='Price',
title=dict(
text='<b><span style="font-size: 10pt">House Prices: Scatter Plot</span> <br> <span style="font-size:5">Variables: size, price</span></b>',
),
)
# Show the plot
fig.show()
Recap
- Measures of linear relationships describe the relationship between two variables.
- Covariance identifies the direction of the relationship between two metrically scaled variables but not the strength.
- The Pearson correlation coefficient measures both the direction and strength of the relationship between two metrically scaled variables.
- If at least one variable is ordinal, the Spearman correlation coefficient is used.
- A scatter plot can visually represent the relationship between two metric variables.
Tasks
Task: Attribute Correlation
Use the following dataset:
from ucimlrepo import fetch_ucirepo
# fetch dataset
cars = fetch_ucirepo(id=9)
# https://archive.ics.uci.edu/dataset/9/auto+mpg
# data (as pandas dataframes)
data = cars.data.features
# Show the first 5 rows
data.head()
- Analyze the correlation between the variables
horsepowerandcylinders. Therefore calculate the covariance, pearson correlation coefficient and spearman correlation coefficient. Interpret the results. - Generate a scatter plot for the variabels
horsepowerandcylinders. Compare the before result with the calculated measures. - Take a closer look on the different variables and the corresponding attribute type. Is there a variable, where the calculation of the correlation makes no sense?
Task: Income vs. Expenditures
Given below are the incomes and weekly consumption expenditures of four households (sample), each measured in euros:
#
import pandas as pd
income = [150, 250, 175, 165]
expenditure = [135, 150, 140, 150]
# convert the lists to pandaframe
df = pd.DataFrame({'income': income, 'expenditure': expenditure})
df.head()
- Calculate the covariance between
incomeandexpenditure. Interpret the result. - Calculate the covariance when
incomeis measured in Euro cents. How does this affect the interpretation? - Switch back to
incomein Euro. Calculate the Pearson correlation coefficient. Interpret the results. - Calculate the correlation coefficient when income is measured in Euro Cents. How does this affect the interpretation?