Sampling
Sample Distribution
In this explanation, we'll talk about creating sample distributions, an essential topic in inferential statistics. This is important for generating confidence intervals and making inferences about a population from a sample, which is a core goal of inferential statistics.
Code
For the upcoming example, the following data will be used:
Creating a Data Distribution
Let’s say we’re interested in finding out the average age of people. While we know there is a wide range of ages, we want to get a more precise understanding. Statistically, this means determining the population parameter for the age of people. However, it’s not feasible to find out the age of every person in the world. Why? There are simply too many people, living in different regions, and new individuals are born while others pass away. Additionally, we might accidentally include the same person more than once, making the task more complicated.
Instead of measuring the entire population, we can take a random sample of people. For example, we could collect the ages of 100 individuals.
One person might be 25 years old, another might be 42 years old, and so on. After gathering the data, we can create a distribution of these ages, often visualized as a histogram, and calculate the sample mean (the average age of the people in our sample).
Code
import random
import numpy as np
import plotly.express as px
import pandas as pd
# Pick a random sample of 100 from the data and calculate the mean
sample = random.sample(list(data.age), 100)
sample_mean = np.mean(sample)
# Count the frequency of each age in the sample
pd.DataFrame(sample)
s_counts = pd.DataFrame(sample).value_counts().sort_index()
s_counts = s_counts.to_frame().reset_index()
# Plot the sample data
fig = px.bar(x = s_counts[0], y=s_counts['count'])
fig.update_traces(marker=dict(color='rgba(0, 65, 110, 0.8)'))
# Add a vertical line for the population mean
fig.add_vline(x=sample_mean, line_dash="dash", annotation_text="Mean: "+str(sample_mean), annotation_position="top right", line_color="#E87F2B")
# Adjust the layout
fig.update_layout(
barmode='overlay',
xaxis_title_text='Age',
yaxis_title_text='Frequency',
title=dict(
text='<b><span style="font-size: 10pt">Age Distribution - Sample 4 (Mean: '+str(sample_mean)+')</span> <br> <span style="font-size:5">Data: UCIML Repo: Adult; variable: age</span></b>',
),
)
fig.show()
Now, the sample mean we calculate from our 100 people is just one estimate of the population's average age.
Outlook
How does this sample mean realate to the actual population mean? And how confident are we, that this sample mean is really close to the population mean? Those are questions we will learn to answer in the upcomming sections about confidence intervals and hypothesis testing.
However, it’s important to understand that this is just one estimate. If we take another random sample of 100 people, we might get a slightly different average because not all individuals are the same age. So, what can we do?
Right, we repeat the experiment! We measure another sample of 100 people and calculate a new sample mean. Note, that there can be an overlap between those two samples (one person was part of the first and the second sample). This is called sampling with replacement.
We notice that the results are similar to the first sample, but not exactly the same.
This difference is known as sampling variability - the natural variation that occurs when taking different samples from the same population. More about this topic will be covered in the Sampling Variability section.
Task: Data Distribution
Use the following dataset:
from ucimlrepo import fetch_ucirepo
# fetch dataset
adult = fetch_ucirepo(id=2)
# https://archive.ics.uci.edu/dataset/2/adult
# data (as pandas dataframes)
data = adult.data.features
# Show the first 5 rows
data.head()
- Pick a random sample of 100 values from the
hours-per-weekattribute - Calculate the mean of this sample
- Plot the sample distribution as a
plotly.expressbar chart. Add vertical line (fig.add_vline) to indicate the sample mean - Calculate the mean of the population (all the entries in the dataset) and compare it with the sample
Creating a Sample Distribution of Means
We can repeat this sampling process multiple times. Let’s say we take N samples. Each sample gives us a new sample mean, and these means will vary slightly due to the natural differences in people's ages. Now, instead of focusing on individual ages (data distribution), we can create a distribution of sample means - a new distribution that shows how the sample estimates themselves vary.
Code
import random
import numpy as np
import plotly.express as px
import pandas as pd
# Function to calculate the mean of the sample
def calculate_sample_mean(sample_size, n_sample):
sample_mean = []
for i in range(n_sample):
sample = random.sample(list(data.age), sample_size)
sample_mean.append(np.mean(sample))
return sample_mean
# Initialize variables
sample_size = 100
number_of_samples = 100
# Calculate the sample means
x1 = calculate_sample_mean(sample_size, number_of_samples)
# Bin the data
x1_binned = pd.cut(x1, bins=np.arange(data.age.min(),data.age.max(),0.1), right=False)
x1_counts = x1_binned.value_counts().sort_index()
# Trim the data to remove the 0.0 values at the start and end
first_non_zero_index = x1_counts.ne(0.0).idxmax()
last_non_zero_index = x1_counts[::-1].ne(0.0).idxmax()
x1_counts_trimmed = x1_counts.loc[first_non_zero_index:last_non_zero_index]
# Convert the index to string
x1_counts_trimmed.index = x1_counts_trimmed.index.astype(str)
# Plot the data
fig = px.bar(x = x1_counts_trimmed.index, y=x1_counts_trimmed)
fig.update_traces(marker=dict(color='rgba(232, 127, 43, 0.8)'))
fig.update_layout(
barmode='overlay',
xaxis_title_text='Age Category',
yaxis_title_text='Frequency',
title=dict(
text='<b><span style="font-size: 10pt">Age Distribution of Sample Means</span><br><span style="font-size: 8pt">Sample Size: 100 | Number of Samples: 100</span> <span style="font-size:5">Data: UCIML Repo: Adult; variable: age</span></b>',
),
)
fig.show()
This distribution of sample means gives us valuable insights about the population. For example, if most of the sample means are very close to each other, we can be more confident that our sample estimates are close to the true population mean. However, if the sample means are widely spread out, it indicates that we might need larger or more representative samples to get a more accurate estimate of the population's true average age.
Code
import random
import numpy as np
import plotly.express as px
import pandas as pd
import plotly.graph_objects as go
# Initialize variables
sample_size = [10, 100, 1000]
number_of_samples = [10, 100, 1000]
# Function to calculate the mean of the sample
def calculate_sample_mean(sample_size, n_sample):
sample_mean = []
for i in range(n_sample):
sample = random.sample(list(data.age), sample_size)
sample_mean.append(np.mean(sample))
return sample_mean
for i in range(3):
# Calculate the sample means
x1 = calculate_sample_mean(sample_size[0], number_of_samples[i])
x2 = calculate_sample_mean(sample_size[1], number_of_samples[i])
x3 = calculate_sample_mean(sample_size[2], number_of_samples[i])
# Bin the data
x1_binned = pd.cut(x1, bins=np.arange(data.age.min(),data.age.max(),0.1), right=False)
x2_binned = pd.cut(x2, bins=np.arange(data.age.min(),data.age.max(),0.1), right=False)
x3_binned = pd.cut(x3, bins=np.arange(data.age.min(),data.age.max(),0.1), right=False)
x1_counts = x1_binned.value_counts().sort_index()
x2_counts = x2_binned.value_counts().sort_index()
x3_counts = x3_binned.value_counts().sort_index()
x1_counts.index = x1_counts.index.astype(str)
x2_counts.index = x2_counts.index.astype(str)
x3_counts.index = x3_counts.index.astype(str)
# Plot the data
fig = px.bar(x = x1_counts.index, y=x1_counts)
fig.update_traces(marker=dict(color='rgba(0, 65, 110, 0.4)'), name='Sample Size = '+str(sample_size[0]), showlegend=True)
fig.add_trace(go.Bar(x = x2_counts.index, y=x2_counts, name='Sample Size = '+str(sample_size[1]), marker=dict(color='rgba(255, 0, 0, 0.4)')))
fig.add_trace(go.Bar(x = x3_counts.index, y=x3_counts, name='Sample Size = '+str(sample_size[2]), marker=dict(color='rgba(0, 255, 0, 0.4)')))
fig.update_layout(
xaxis_range=[150,300],
barmode='overlay',
xaxis_title_text='Age Category',
yaxis_title_text='Frequency',
title=dict(
text='<b><span style="font-size: 10pt">Age Distribution of Sample Means</span><br><span style="font-size: 8pt">Number of Samples: ' + str(number_of_samples[i]) + '</span> <span style="font-size:5">Data: UCIML Repo: Adult; variable: age</span></b>',
),
)
fig.show()
Different Types of Sample Distribution
While we have been using the mean as an example, the same approach can be applied to other statistics as well. For instance, you could look at the variance. If you're interested in knowing how much age varies across a population, you could calculate the variance or standard deviation for each sample.
By repeating the process with multiple samples, you can then create a sample distribution of these variance estimates. This allows you to find the average variance across all the samples, giving you a better understanding of how much variability exists in the ages of the overall population.
Task: Sample Distribution
Use the the dataset from before and work on the following tasks:
- Calculate the sample distribution of the standard deviation for a
sample_size = 100andnumber_of_samples = 100and visualize it in bar chart - Calculate the standard deviation of the population and compare the results.
- Again, visualize the sample distribution of the standard deviation now for
sample_size = [10, 100, 1000]andnumber_of_samples = 100
Sample Distribution of Differences
Let's shift the focus of our example and explore sample estimate differences instead of just looking at one parameter. The question we want to explore is: are widowed individuals generally older than people who have never been married? While it seems obvious that widowed individuals are likely to be older, since people tend to marry before becoming widowed, let’s frame this question statistically to better understand the process.
We start by imagining two populations: one of widowed individuals and one of never-married individuals.
data_widowed = data[data['marital-status'] == 'Widowed'].age
data_never_married = data[data['marital-status'] == 'Never-married'].age
Since it’s not practical to measure the age of every person in both groups, we take a random sample from each. For example, we could sample 100 widowed individuals and 100 people who have never been married,
sample_widowed = random.sample(list(data_widowed), 100)
sample_never_married = random.sample(list(data_never_married), 100)
and then calculate the average age for each group.
sample_widowed_mean = np.mean(sample_widowed)
sample_never_married_mean = np.mean(sample_never_married)
Let’s say, in the first sample, the average age of the widowed group is 70 years, and the average age of the never-married group is 45 years. The difference between these averages is 25 years. However, this is just one sample, and the difference might vary slightly if we take another random sample. So, we repeat the process with a second random sample and find that the difference this time is 24 years.
Code
number_of_samples = 100
sample_size = 100
def calculate_sample_mean(sample_size, n_sample, data):
sample_mean = []
for i in range(n_sample):
sample = random.sample(list(data), sample_size)
sample_mean.append(np.mean(sample))
return sample_mean
x1 = calculate_sample_mean(sample_size, number_of_samples, data_widowed)
x2 = calculate_sample_mean(sample_size, number_of_samples, data_never_married)
x1_binned = pd.cut(x1, bins=np.arange(data.age.min(),data.age.max(),0.1), right=False)
x2_binned = pd.cut(x2, bins=np.arange(data.age.min(),data.age.max(),0.1), right=False)
x1_counts = x1_binned.value_counts().sort_index()
x2_counts = x2_binned.value_counts().sort_index()
x1_counts.index = x1_counts.index.astype(str)
x2_counts.index = x2_counts.index.astype(str)
fig = px.bar(x = x1_counts.index, y=x1_counts)
fig.update_traces(marker=dict(color='rgba(0, 65, 110, 0.4)'), name='Widowed', showlegend=True)
fig.add_trace(go.Bar(x = x2_counts.index, y=x2_counts, name='Never-Married', marker=dict(color='rgba(255, 0, 0, 0.4)')))
fig.update_layout(
xaxis_range=[80,460],
barmode='overlay',
xaxis_title_text='Age Category',
yaxis_title_text='Frequency',
title=dict(
text='<b><span style="font-size: 10pt">Age Distribution of Sample Means</span><br><span style="font-size: 8pt">Sample Size: 100 | Number of Samples: 100</span> <span style="font-size:5">Data: UCIML Repo: Adult; variable: age, maritial-statur</span></b>',
),
)
fig.show()
By repeating this process across many samples, we can build a distribution of the differences in average age between the widowed and never-married groups. This distribution allows us to see how consistent the differences are across various samples. If the differences are relatively consistent, we can be confident that widowed individuals tend to be older than those who have never been married. If the differences vary widely, we may need larger or more representative samples to draw a reliable conclusion.
Code
number_of_samples = 100
sample_size = 100
def calculate_sample_mean_diff(sample_size, n_sample, data1, data2):
sample_mean_diff = []
for i in range(n_sample):
sample1 = random.sample(list(data1), sample_size)
sample2 = random.sample(list(data2), sample_size)
sample_mean_diff.append(np.mean(sample1)-np.mean(sample2))
return sample_mean_diff
x1 = calculate_sample_mean_diff(sample_size, number_of_samples, data_widowed, data_never_married)
x1_binned = pd.cut(x1, bins=np.arange(data.age.min(),data.age.max(),0.1), right=False)
x1_counts = x1_binned.value_counts().sort_index()
first_non_zero_index = x1_counts.ne(0.0).idxmax()
last_non_zero_index = x1_counts[::-1].ne(0.0).idxmax()
x1_counts_trimmed = x1_counts.loc[first_non_zero_index:last_non_zero_index]
x1_counts_trimmed.index = x1_counts_trimmed.index.astype(str)
fig = px.bar(x = x1_counts_trimmed.index, y=x1_counts_trimmed)
fig.update_traces(marker=dict(color='rgba(0, 65, 110, 0.4)'))
fig.update_layout(
barmode='overlay',
xaxis_title_text='Age Category',
yaxis_title_text='Frequency',
title=dict(
text='<b><span style="font-size: 10pt">Age Distribution of Sample Differences (widowed vs. never-married)</span><br><span style="font-size: 8pt">Sample Size: 100 | Number of Samples: 100</span> <span style="font-size:5">Data: UCIML Repo: Adult; variable: age, maritial-statur</span></b>',
),
)
fig.show()
Sign (+/-) of the Estimator
It’s also important to note that, just like in other statistical comparisons, the sign of the difference (positive or negative) doesn’t affect the actual result. For instance, if we subtract the average age of the never-married individuals from that of the widowed group, we’ll get a positive difference. But if we subtract the widowed individuals' ages from the never-married individuals' ages, the result will be negative. Statistically, both results show the same difference; it’s just a matter of interpretation.
Random & Representative Sampling
To give another example, suppose we wanted to compare the ages of people from different regions, say those living in urban areas versus rural areas. Even if there’s no significant age difference between the two groups, each sample might show slight variations due to natural differences in the sample. By taking many samples, we could build a distribution of differences and better understand whether any observed difference is consistent.
This also emphasizes the importance of random and representative sampling. If we don’t carefully select our samples, we might get misleading results. For instance, imagine comparing life expectancy in two countries, but we only sample older people in one country and younger people in the other. The resulting data would falsely suggest a significant difference in life expectancy between the countries, when in reality, the sampling was biased. To avoid this, we need to ensure that our samples fairly represent the populations we’re studying.
Sampling Varibility
Variability is a crucial concept in statistics and probability and plays a significant role in scientific research. It’s also one of the main sources of frustration for researchers because it can make results less predictable and more complex. Let’s dive into the idea of sampling variability, where this variability comes from, and why understanding it is so important.
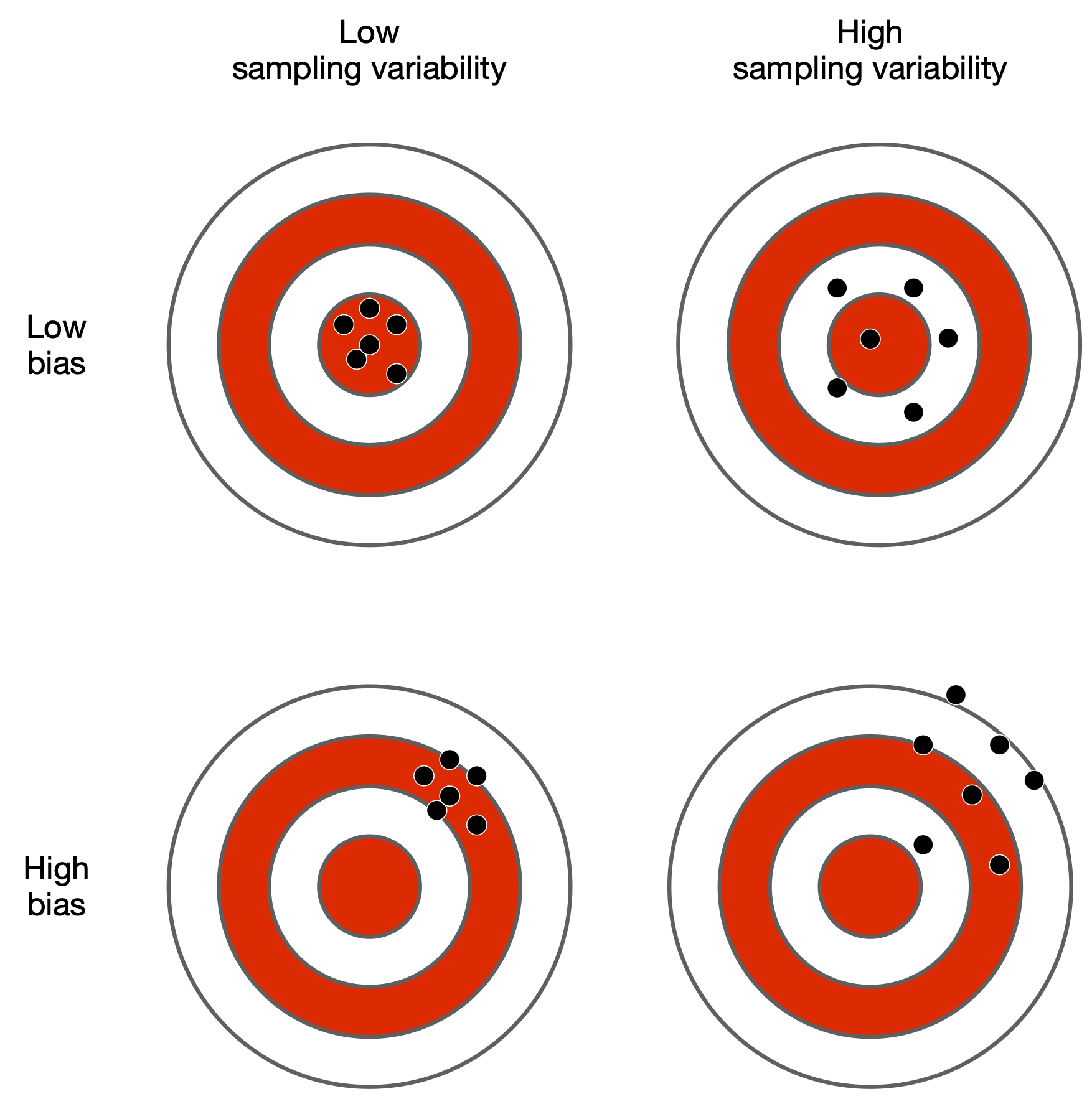
Imagine you have a research question: What is the average age of workers in a factory? To answer this, you decide to measure the age of a few workers. Let's say you randomly select one worker who is 45 years old. Is this the average age of all workers in the factory? Most likely not. So, you keep asking more workers and get different ages like 50, 34, 60, etc. This difference in ages between the workers is an example of sampling variability - the natural differences that occur when taking samples from a population.
Even though the overall population (all workers in the factory) has a true average age, you will get slightly different values from each sample you take. This is why relying on just one sample to represent an entire population can lead to inaccurate results. The goal is to reduce this variability by taking more samples and averaging them to get a more reliable estimate of the population’s average age like we did before.
Definition: Sampling Variability
Using the
- same measurement (e.g. mean) on
- different samples (e.g. age of 100 people) from the
- same population (e.g. age of all people in the world) can lead to
- different values (e.g. 47 or 52,...)
Sources of Sampling Variability
-
Natural Variation: In many fields, especially biology and sociology, natural variation occurs. In our factory example, workers come from different backgrounds and generations, which naturally causes variability in their ages.
-
Measurement Noise: In some cases, the tools or methods used to gather data may introduce variability. For instance, if you’re using a tool with low precision, like a scale that only measures in whole kilograms when you need to measure in grams, you introduce errors in your measurements.
-
Complex Systems: Variability can also come from the complexity of the system being studied. In the factory example, factors like different hiring policies, regional differences, or workforce changes can add to the variation in workers’ ages.
-
Uncontrollable Factors: Some sources of variability, like random or unpredictable events, are outside of the researcher's control. For example, economic conditions might affect the hiring or retirement age of workers, adding unpredictability.
Dealing with Sampling Variability
To reduce the impact of sampling variability, one of the most effective strategies is to take multiple samples. Instead of measuring just a few workers' ages, you would gather information from a larger sample, maybe 100 or more workers, and calculate the average age. The more samples you take, the closer you get to the true average age of the entire population. This is based on the law of large numbers, which states that as you increase the number of samples, the average of those samples will get closer to the population mean.
Additionally, statistical tools like confidence intervals can help you understand how close your sample estimate is to the actual population parameter. Confidence intervals provide a range within which the true average age of the factory workers is likely to fall, giving a better sense of the precision of your estimate.
Sampling Variability vs. Reliable Estimates
So as we mentioned before, we can deal with the sampling variablility by using a larger sample. So we can repeat the experiment from before by randomly selecting a group of different people and calculating the mean of their age. We can do that, by looping through different sample sizes
samplesizes = np.arange(5,1000)
for sampi in range(len(samplesizes)):
sample = random.sample(list(data.age), samplesizes[sampi])
and for each sample, we calculate the mean age and then plot the result, showing how the mean changes with different sample sizes. Now, let’s consider: what do we expect to happen? Intuitively, as the sample size grows, we’d expect the sample mean to get closer and closer to the population mean, which represents the true average. So, as we increase the sample size, the variation in the sample means should decrease, and the results should start to stabilize around the population mean.
Code
## Repeat for different sample sizes
samplesizes = np.arange(5,1000)
samplemeans = np.zeros(len(samplesizes))
for sampi in range(len(samplesizes)):
sample = random.sample(list(data.age), samplesizes[sampi])
samplemeans[sampi] = np.mean(sample)
fig = px.line(x=samplesizes, y=samplemeans,markers=True)
fig.update_traces(line=dict(color='rgba(0, 65, 110, 0.6)'))
# Add a vertical line for the population mean
fig.add_hline(y=np.mean(data.age), line_dash="dash", annotation_text="Mean: "+str(np.mean(data.age)), annotation_position="top right", line_color="#E87F2B")
fig.update_layout(
xaxis_range=[samplesizes.min()-10,samplesizes.max()+10],
barmode='overlay',
yaxis_title_text='Mean Value',
xaxis_title_text='Sample Size',
title=dict(
text='<b><span style="font-size: 10pt">Sample Means of Age</span><br> <span style="font-size:5">Data: UCIML Repo: Adult; variable: age</span></b>',
),
)
fig.show()
When we run the experiment, we see that the blue line represents the sample means, and they’re fluctuating quite a bit. The orange line is the true population mean, which is known in advance. While the sample means do start to get closer to the orange line as the sample size increases, they still bounce around quite a lot, even with large samples of up to 1,000 people. This variation is normal for sampling and doesn’t indicate a problem. In fact, it’s expected due to the natural randomness in sample selection.
To show something interesting, we take the mean of several sample means (in this case 10)
By averaging these sample means together, we get a result that’s much closer to the population mean.
As we increase the number of sample means we average, the average gets even closer to the true population mean.
This leads to an important discovery: while individual sample means might not perfectly match the population mean, averaging over multiple sample means brings us much closer to the true value. This concept ties into two key statistical principles - the law of large numbers and the central limit theorem.
Task: Sampling Variability
Use the the dataset from before and work for the variable hours-per-week on the following tasks:
- Calculate the standard deviation for
sample_size = np.arange(5,1000) - Calculate the standard deviation of the population
- Visualize the results as shown above (incl. standard deviation of the population using
fig.add_hline) - Calculate the mean of the sample standard deviation for the first
10,100and1000samples