Introduction

Project Setup
This chapter serves as an introduction to the topic of computer vision. We'll explore various tasks, demonstrating their use with code snippets. Even though this is just an introductory chapter and you might not grasp all the details yet, we encourage you to run the code on your own computer.
To follow along, we recommend setting up a new project folder with a Jupyter notebook. Additionally, create a new virtual environment and activate it. Install the required packages:
Your project structure should look like this:
Computer Vision is a field of artificial intelligence that enables machines to interpret and understand the visual world. By using digital images from cameras and videos along with deep learning models, machines can accurately identify and classify objects - and then react to what they "see."
In this introduction, we'll delve into the basics of computer vision, its challenges, and how it's interconnected with other fields. Let's embark on this visual journey together!
What Is Computer Vision?
Before diving into computer vision, let's briefly touch upon artificial intelligence (AI). AI is a broad field aiming to create systems capable of performing tasks that typically require human intelligence. As one of the pioneers of AI, John McCarthy, described it:
"An attempt will be made to find how to make machines use language, form abstractions and concepts, solve kinds of problems now reserved for humans, and improve themselves."
-- John McCarthy
Artificial Intelligence is a multidisciplinary field divided into several subfields, each contributing to simulating intelligent behavior in machines. These include:
- Machine Learning
- Natural Language Processing
- Robotics
- Computer Graphics
- Computer Vision
These subfields are interconnected; advancements in one often benefit the others. For instance, computer vision is essential in robotics for environment perception and in natural language processing for image captioning.
But now we still want to know: What is computer vision exactly?
At its core, computer vision seeks to automate tasks that the human visual system can do. It involves techniques for acquiring, processing, analyzing, and understanding images to produce numerical or symbolic information.

{kind=link}
Interesting Fact
Did you know, that over 50% of the processing in the human brain is devoted directly or indirectly to visual information (Source: MIT News)
In other words, computer vision transforms visual data into meaningful information. Now, let's explore some typical computer vision tasks and see how they come to life through examples you can try yourself!
Typical Computer Vision Tasks
Classification
Assigning objects within an image to predefined categories or classes.
Example: Classification
Localization
Determining the exact location of an object within an image.
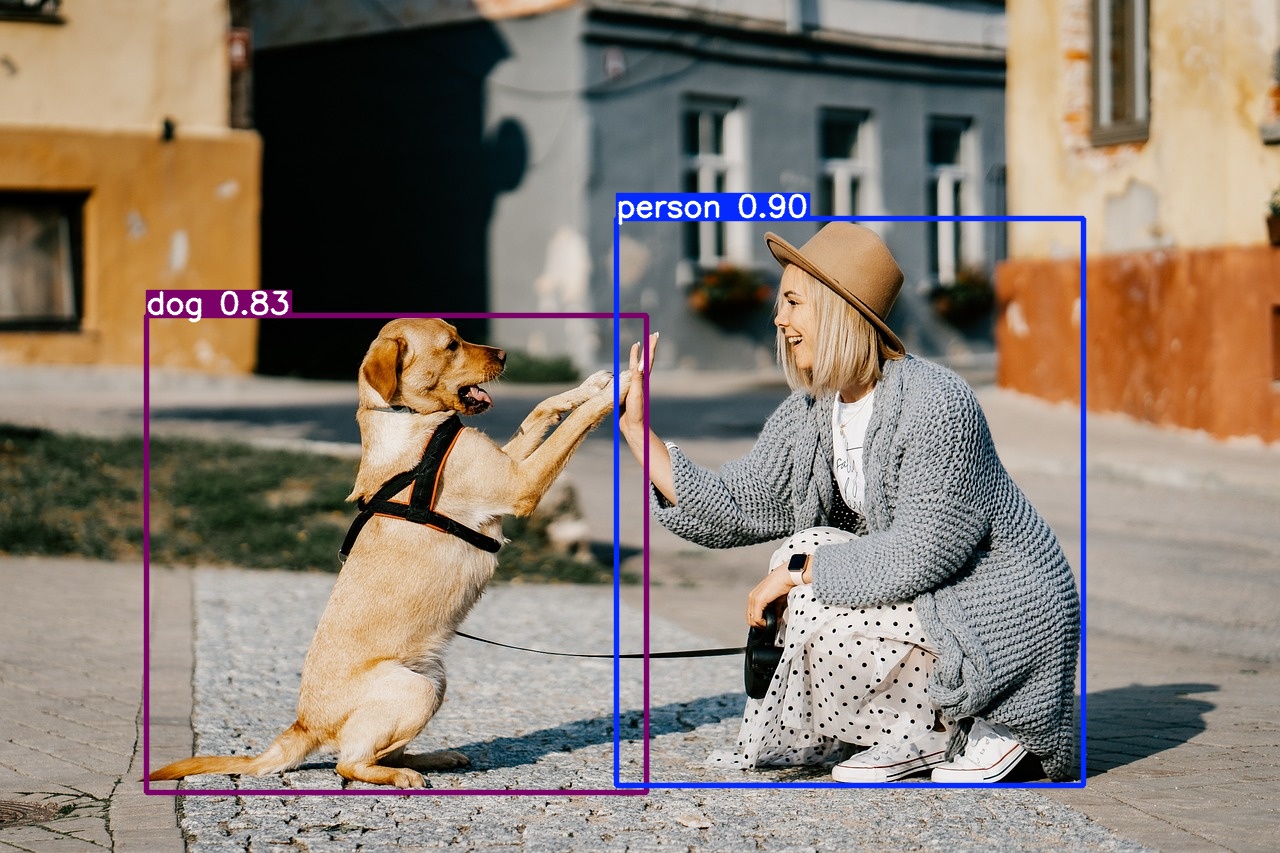
Detection
Identifying and locating multiple objects within an image, effectively combining classification and localization.
Example: Detection
-
Input

-
Output
Segmentation
Precisely delineating the pixels that belong to an object, separating it from the background.
Example: Segmentation
-
Input
-
Output

Tracking
Monitoring the movement of objects over time in videos or live streams, analyzing factors like velocity and relative position.
Example: Tracking
-
Input

-
Output

Code
from collections import defaultdict
import cv2
import numpy as np
from ultralytics import YOLO
# Load the YOLO11 model
model = YOLO("yolo11n.pt")
# Open the video file
video_path = "street2.mp4"
cap = cv2.VideoCapture(video_path)
# Store the track history
track_history = defaultdict(lambda: [])
video = cv2.VideoWriter("output.mp4", 0, 25, (960,540))
# Loop through the video frames
while cap.isOpened():
# Read a frame from the video
success, frame = cap.read()
if success:
# Run YOLO11 tracking on the frame, persisting tracks between frames
results = model.track(frame, persist=True, classes=[2])
# Get the boxes and track IDs
boxes = results[0].boxes.xywh.cpu()
track_ids = results[0].boxes.id.int().cpu().tolist()
# Visualize the results on the frame
annotated_frame = results[0].plot()
# Plot the tracks
for box, track_id in zip(boxes, track_ids):
x, y, w, h = box
track = track_history[track_id]
track.append((float(x), float(y))) # x, y center point
if len(track) > 30: # retain 90 tracks for 90 frames
track.pop(0)
# Draw the tracking lines
points = np.hstack(track).astype(np.int32).reshape((-1, 1, 2))
cv2.polylines(annotated_frame, [points], isClosed=False, color=(230, 230, 230), thickness=10)
# Display the annotated frame
cv2.imshow("YOLO11 Tracking", annotated_frame)
video.write(annotated_frame)
# Break the loop if 'q' is pressed
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else:
# Break the loop if the end of the video is reached
break
# Release the video capture object and close the display window
cap.release()
cv2.destroyAllWindows()
video.release()
Optical Character Recognition
Recognizing and extracting printed or handwritten text from images, enabling machines to read and process written information.
Example: OCR
-
Input

-
Output
>>> OutputLAN DOR. CHAPTER IL BIRTH AND PARENTAGE—SCHOOL — COLLEGE. (1775 —1794.) Few men have ever impressed their peers so much, or the general public so little, as Watrer Savage Lanpor. Of all celebrated authors, he has hitherto been one of the least popular. Nevertheless he is among the most strik- ing figures in the history of English literature ; striking alike by his character and his powers. Personally, Landor exercised the spell of genius upon every one who came near him. His gifts, attainments, impetuosities, his originality, his force, his charm, were all of the same conspicuous and imposing kind. Not to know what is to be known of so remarkable a man is evidently to be a loser. Not to be familiar with the works of so noble
Code
Warning
To run the code, you need to install tesseract on your PC. This can be a tricky process, especially on MacOS. Therefore it is okay to skip this example if you want.
Facial Recognition and Analysis
Identifying individuals based on their facial features and recognizing various facial expressions.
Example: Facial Recognition
-
Input

-
Output

Code
# Load Packages
import cv2
import matplotlib.pyplot as plt
from deepface.modules import streaming # Corrected import path
from deepface import DeepFace
# Load Image
img_path = "pic_cv_approaches/obama.jpg"
img = cv2.imread(img_path)
raw_img = img.copy()
# Analyze Image
demographies = DeepFace.analyze(img_path=img_path, actions=("age", "gender", "emotion"))
demography = demographies[0]
# Get Region of Interest
x = demography["region"]["x"]
y = demography["region"]["y"]
w = demography["region"]["w"]
h = demography["region"]["h"]
# Overlay Emotion
img = streaming.overlay_emotion(img=img, emotion_probas=demography["emotion"], x=x, y=y, w=w, h=h)
# Overlay Age and Gender
img = streaming.overlay_age_gender(img=img, apparent_age=demography["age"], gender=demography["dominant_gender"][0:1], x=x, y=y, w=w, h=h)
# Display Image
plt.imshow(img[:, :, ::-1])
plt.axis('off')
plt.show()
# Save the image with overlays
cv2.imwrite("obama_out.jpg", img)
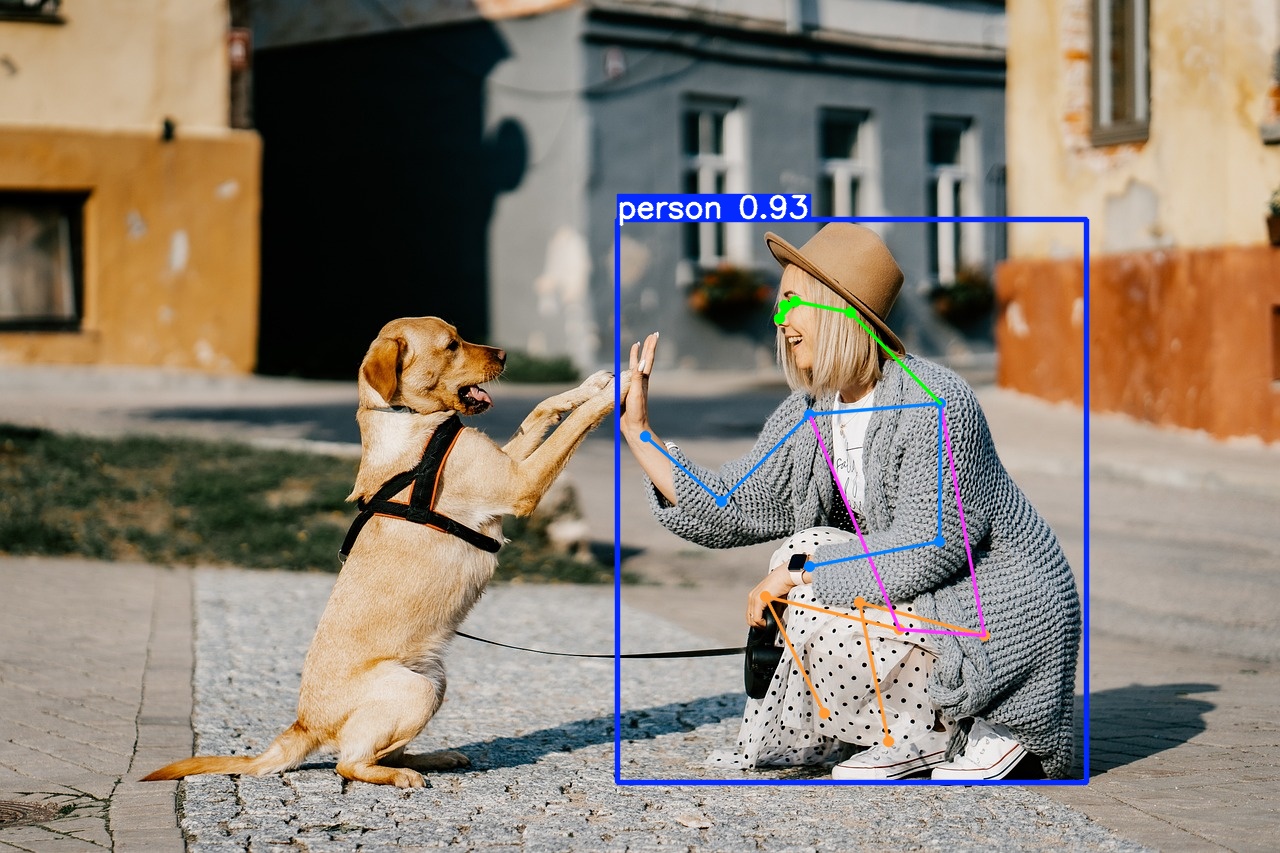
Pose Estimation
Determining the position and orientation of an object or person relative to a reference point or coordinate system.
Example: Pose Estimation
-
Input
-
Output
These tasks represent the core of computer vision, each contributing to its wide-ranging real-world applications. From enabling machines to read and understand handwritten documents to enhancing interactive gaming experiences through accurate motion tracking, the advancements in computer vision are transforming industries and everyday life.
And: as you can see, they're not just theoretical concepts - you can try them out yourself !
Applications
Computer vision has a wide range of applications across various industries.
Possible Applications for Computer Vision
Robots use computer vision to navigate and interact with their environment.

Self-driving cars rely heavily on computer vision to perceive the road and make driving decisions.

Computer vision aids in medical imaging for diagnostics and treatment planning.

{kind=link}
Automated inspection systems detect defects in manufacturing processes.

Augmented reality shopping experiences enhance customer engagement.

Used for security and authentication purposes.

{kind=link}
How can Machines "See"? 
When we look at the world, our eyes receive light reflected from objects. Similarly, cameras capture light to create images.
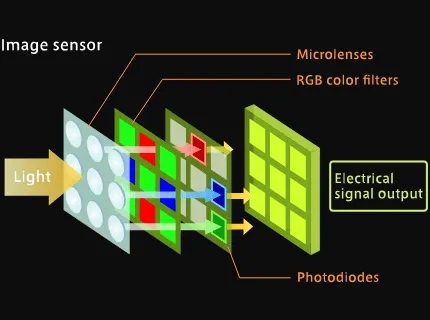
However, interpreting these images to understand the scene involves complex algorithms that can discern patterns, shapes, and colors. This process involves several steps:
- Image Acquisition: Capturing the visual data using cameras or sensors.
- Preprocessing: Enhancing image quality and correcting distortions.
- Feature Extraction: Identifying edges, textures, and other significant parts of the image.
- High-Level Processing: Recognizing objects, understanding scenes, and making decisions.
Challenges in Computer Vision
Despite the advancements, computer vision faces several challenges. Let's explore them.
-
Inverse Problem
One of the fundamental challenges in computer vision is the inverse problem: Reconstructing a 3D scene from a 2D image is challenging because multiple 3D scenes can produce the same 2D projection.
-

(Source: mosso on Wikipedia) -

(Source: Palazzi et al at Computer.org) -
Variability Due to Viewpoint
An object can look vastly different from various angles. For example, a car viewed from the front, side, or top presents different shapes and features, complicating recognition tasks.
-
Deformation
Non-rigid objects, like clothing or human bodies, can change shape, making it challenging to maintain consistent recognition.
-

-

-
Occlusion
Objects in images often block parts of other objects. Detecting partially visible objects requires algorithms to infer the hidden parts.
-
Illumination
Lighting conditions can alter the appearance of objects. An apple under bright sunlight looks different from one under indoor lighting.
-

(Source: Flocutus) -

(Source: Osi on Wikipedia) -
Motion Blur
Movement during image capture can blur images, obscuring details necessary for recognition.
-
Optical Illusions
Our perception can be deceived by optical illusions, where our brain interprets images differently from the actual measurements.
-

-

(Source: Nizar Massouh on ResearchGate) -
Intra Class Variation
Objects within the same category can look very different.Chairs come in numerous designs—armchairs, stools, recliners—but they all serve the same function. Recognizing all variations as "chairs" is challenging for computer vision systems.
-
Number of Categories
There are thousands of object categories, each with its own variations. Building systems that can recognize all of them requires extensive data and sophisticated algorithms.
-

(Source: Cees Snoek on ResearchGate)
{kind=link}
{kind=link}
By understanding these challenges, you're better equipped to appreciate the complexities involved in teaching machines to see.
Congratulations! You've taken your first steps into the world of computer vision. Feel free to experiment with the code examples provided and explore further. In the next chapters, we'll delve deeper into specific algorithms and techniques.
See you in the next chapter! 👋